

前面的实验中,我们模型的输入都是一些简单的数值,比如线性回归章节中的8个特征属性,以及MLP实验中的x,难道AI只能处理这些简单的数据,做一些简单的预测任务吗?
当然不是,在本节实验中,我们将立足计算机视觉领域,探索AI模型在视觉方面的强大能力,我们本次实验将聚焦于图像分类的任务,基于预训练模型,快速实现图像的分类。
数据加载:读取与显示图片
既然要对图像进行识别分类,那么我们要让AI能够看得懂图,在看懂之前,得要让他先看到图,对于一个图片,我们该如何读取并转成能够输入到模型中的格式呢?
在Python中,读取图片主要有两种方式,对应分别使用PIL(Python Imaging Library)库和OpenCV库。
PIL不支持Python3,我们为了在Python3中使用PIL,可以安装Pillow库。可以通过pip安装:
pip install pillow
安装完毕后,我们可以使用Image.open()读取图片。
from PIL import Image
image_path = '../../shixunfiles/bus.jpg'
image = Image.open(image_path)
# 显示图片信息
print(image)
print("图片格式:", image.format)
print("图片大小(宽度, 高度):", image.size)
print("图片模式:", image.mode)输出结果:
图片格式: JPEG
图片大小(宽度, 高度): (810, 1080)
图片模式: RGB
需要注意的是,使用PIL.Image.open(),是以 (w, h) 即“宽 x 高”的方式读取图片的,数据类型是PIL.Image.Image。
如果我们需要将其作为数据传递到模型中,显然不能使用此类型,可以将图片转为numpy的ndarray或pytorch的tensor类型。
# 将图片转换为 NumPy 数组
import numpy as np
image_array = np.array(image)
print("numpy 数组形状:", image_array.shape)输出结果:
NumPy 数组形状: (1080, 810, 3)
输出结果会发现,这里转换为ndarray数据类型之后,宽高的顺序也变化了,这里一定要注意:转为numpy.ndarray后,格式为(h, w, c)即“高 x 宽 x 通道”。
接着,我们将其转换成pytorch的tensor类型。
from torchvision.transforms import transforms
transform = transforms.ToTensor()
image_tensor = transform(image)
print("torch 张量形状:", image_tensor.shape)输出结果:
torch 张量形状: torch.Size([3, 1080, 810])
可以看到,转成张量之后,形状也发生了变化,格式为(c, h, w)即“通道 x 高 x 宽”。
接着我们尝试使用OpenCV进行图片的读取。假如你没有安装OpenCV,也可以使用pip进行安装:
pip install opencv-python
安装之后注意导入的包名不是opencv,而是cv2。使用imread()方法来进行图片的读取。
import cv2
# 读取图片
image_path = "../../shixunfiles/bus.jpg"
image = cv2.imread(image_path)
print(type(image))
print("图片形状(高度, 宽度, 通道数):", image.shape)输出结果:
图片形状(高度, 宽度, 通道数): (1080, 810, 3)
cv2.imread()返回的结果直接就是一个numpy的数组,十分方便。
以上两种库用于读取图片都是可以的,但是要注意的是,PIL读取的图片的像素顺序是RGB,而OpenCV读取的图片的像素顺序是BGR,这里要作出区分
读取图像之后,我们可以将其展示出来,以验证我们读取是否成功。
import cv2
import matplotlib.pyplot as plt
# 使用 OpenCV 加载图像
image = cv2.imread("../../shixunfiles/bus.jpg")
# 将图像从 BGR 转换为 RGB(OpenCV 默认读取为 BGR 格式)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 显示图像
plt.imshow(image_rgb)
plt.show()
保留坐标轴可以让我们更清楚的了解图像的大小,可以看到坐标轴的刻度单位就是像素,我们的图片高1080,宽810,可以判断展示的图片与原图像一致。
简单模型应用:使用预训练模型进行图片分类
首先解释一下什么是预训练模型,顾名思义就是预先训练好的模型。对于希望学习算法或者仅仅想尝试一下模型效果的人来说,使用预先训练好的模型就是一个非常好的解决方案,不过预训练模型不仅仅只有方便使用这一个作用。对于想要训练自己的模型的人来说,首先很难获取大量的数据集,而数据集不够大,模型再稍微复杂一些就会很容易造成过拟合。而预训练模型正是提供了一个解决方案,利用在大规模数据集上训练好的一个模型,用于特征提取或者作为初始参数,这样在自己数据集上微调(fine-tuning),既可以节省时间,又能实现较好的效果。
本小节我们将利用ResNet18预训练模型进行图片分类,ResNet(Residual Network)是一种经典的深度学习模型,它仅靠引入了残差连接(Residual Connection)就大幅度提高了模型的性能,解决了深层神经网络梯度消失的问题。
在torchvision.model包中定义了许多模型用于完成图像方面的深度学习任务,我们可以从这里加载ResNet18模型。
import torchvision.models as models
# 加载预训练模型(ResNet18)
model = models.resnet18(pretrained=True)
model.eval() # 设置为评估模式,不会进行梯度的计算当设置pretrain参数为True时,运行这行代码时,会从网上下载模型的权重并保存在本地,带有训练好的权重的网络自然就是预训练模型了。我们可以打印模型的结构:
print(model)输出结果:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
得到预训练模型之后,我们似乎就可以传入图像进行分类的,不过我们还需要对输入的数据进行处理,我们可以利用torchvision.transforms定义处理步骤:
from torchvision.transforms import transforms
# 定义图像预处理步骤
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])你可能会纳闷:为什么要这么做?因为ResNet18是在ImageNet上训练出来的,ImageNet包括了1000种分类超过1000万张图片,在训练ResNet18时,输入的数据进行了如上的预处理:首先将图像的短边调整为了56像素,长边按比例缩放,接着从图像中心裁剪出 224x224 的区域。然后转换成pytorch的张量。并及将像素值进行了归一化:0-255=>0-1,最后进行标准化,类似我们之前用到的,对图像的每一个通道进行标准化处理,使用的就是整个数据集的均值和标准差,也就是最后一步所用到的值。所以我们使用ResNet18预训练模型时,输入图像也要做这样的预处理,这样输入的数据分布和训练时的一致,我们可以得到准确的结果。
接着我们就可以使用第一小节学到的内容,读取图片,并经过预处理步骤,得到可以传递进模型的格式。
from PIL import Image
# 加载并预处理图片
image_path = "../../shixunfiles/car.jpg" # 图片路径
image = Image.open(image_path)
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0) # 增加一个批次维度 真实的测试数据应该是一个数据集这里使用一张汽车的图片,作为测试数据。

图 58 测试数据
接着就可以使用预训练模型进行分类了,如果我们使用GPU,可以加速推理过程,使用CPU也是可以的,只不过速度上会慢些。
import torch
# 使用 GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input_batch = input_batch.to(device)
model = model.to(device)
# 前向传播 但是不计算梯度
with torch.no_grad():
output = model(input_batch)
# 打印预测结果
print("预测结果:", output.shape)
# 获取预测结果
probabilities = torch.nn.functional.softmax(output[0], dim=0) # 计算最大的五个概率
top5_prob, top5_catid = torch.topk(probabilities, 5) # 获取前 5 个类别
print(top5_prob)
print(top5_catid)输出结果:
预测结果: torch.Size([1, 1000])
tensor([0.5696, 0.1779, 0.1676, 0.0505, 0.0121], device='cuda:0')
tensor([817, 751, 479, 656, 436], device='cuda:0')
预测的结果是一个大小为1000的向量,正好对应的1000个类别,每个类别上的值表示模型认为它属于该类的可能性大小,我们可以使用softmax函数对其计算概率,这样可以将所有的值映射到0-1之间,且求和为1,然后取前五个最大的概率,就是模型认为最有可能的类别,这里的类别是使用索引代替的,所以我们并不能直观地看出模型判断的类别是什么,可以在网上查找ImageNet对应的索引和类别,然后下载到本地,方便后续调用。
这里我们将所有索引序号和类别的映射关系存放在了一个json文件中:

然后基于这个json文件,根据索引拿到后面的类别:
import json
# 加载类别文件
with open("../../shixunfiles/classes.json", "r") as f:
classes = json.load(f)
# 获取前五个类别名称
top5_classes = [classes[str(cat_id.item())] for cat_id in top5_catid]
# 打印结果
for i, class_name in enumerate(top5_classes):
print(f"Top {i+1}: {class_name} (概率: {top5_prob[i] * 100:.2f}%)")输出结果:
Top 1: sports car, sport car (概率: 56.96%)
Top 2: racer, race car, racing car (概率: 17.79%)
Top 3: car wheel (概率: 16.76%)
Top 4: minivan (概率: 5.05%)
Top 5: beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon (概率: 1.21%)
模型大概率认为是跑车或者是赛车,说明ResNet18预训练模型分类还是很准确的。
结果的可视化
使用单张图片简单地测试了一下ResNet18的效果后,我们可以使用现成的数据集进行更加准确的性能评估,ResNet18在ImageNet上训练,所以我们可以直接使用ImageNet的测试集进行评估,ImageNet数据集通常指的是ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)比赛用的子数据集,它包括1281167张图片+标签的训练集,50000张图片+标签的验证集和100000张图片的测试集,由于测试集没有标签,所以我们可以使用验证集代替测试集进行一个简单的实验。
首先,验证集的标注信息为xml文件,其中用于表示类别的标注为wordNet ID,而不是刚刚的0-999的索引,所以我们需要一个wordNet ID和刚刚的索引的映射关系。我们提供了现成的映射json文件。
下面给出完整的用于在测试集上评估模型性能并生成评估文件的代码。我们不需要去关注其中的细节,只要知道整体过程就是利用预训练模型ResNet18在ImageNet的验证集上进行了测试并记录评估信息。注意:在数据的预处理部分,我们做出了一些改进,因为真实的ImageNet数据集可能包括黑白的单通道图像,所以可能会遇到一些问题,所以我们统一改成3个通道。由于测试集共有50000张图片,所以进行测试会花费一定的时间,如果没有GPU,可能会消耗较长时间,所以我们可以只取部分的数据进行测试,比如这里我们只取5000张。
解压图片代码:
import tarfile
def extract_tar_file(tar_path, extract_path='.'):
with tarfile.open(tar_path, 'r') as tar:
tar.extractall(path=extract_path)
print(f'Files extracted to {extract_path}')
extract_tar_file('../../shixunfiles/imagenet_data.tar', '../')评估代码:
import os
import torch
import torchvision.models as models
from torchvision.transforms import transforms
from PIL import Image
import json
import xml.etree.ElementTree as ET
from torchvision.models import ResNet18_Weights
import random # 导入 random 模块
# 定义图像预处理步骤
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.Lambda(lambda x: x.convert("RGB")), # 将黑白图片转换为三通道
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载预训练模型(ResNet18),使用 weights 参数
weights = ResNet18_Weights.IMAGENET1K_V1
model = models.resnet18(weights=weights)
model.eval() # 设置为评估模式
# 使用 GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 加载类别映射文件
with open("../../shixunfiles/imagenet_class_index.json", "r", encoding="utf-8") as f:
class_index = json.load(f)
# 构建 WordNet ID 到索引的映射
wordnet_id_to_index = {v["id"]: int(k) for k, v in class_index.items()}
# 构建索引到类名的映射
index_to_class_name_zh = {int(k): v["name_zh"] for k, v in class_index.items()}
index_to_class_name_en = {int(k): v["name_en"] for k, v in class_index.items()}
# 定义图片和标注文件夹路径
images_folder = "../imagenet_data/images"
annotations_folder = "../imagenet_data/annotations"
# 获取所有图片文件
image_files = [f for f in os.listdir(images_folder) if f.endswith(('.jpg', '.png', '.JPEG'))]
# 随机选择部分图片
random.seed(42) # 设置随机种子以确保结果可复现
sample_size = 5000 # 随机选择的图片数量
sampled_image_files = random.sample(image_files, sample_size)
# 初始化评估结果
evaluation_results = {
"total_images": 0, # 总图片数
"correct_predictions": 0, # Top-1 正确预测数
"correct_top5_predictions": 0, # Top-5 正确预测数
"incorrect_predictions": 0, # Top-1 错误预测数
"details": [] # 每张图片的详细评估信息
}
# 遍历每张图片
for image_file in sampled_image_files:
# 加载图片
image_path = os.path.join(images_folder, image_file)
try:
image = Image.open(image_path)
input_tensor = preprocess(image)
input_tensor = input_tensor.unsqueeze(0).to(device) # 增加批次维度并移动到设备
# 前向传播(不计算梯度)
with torch.no_grad():
output = model(input_tensor)
# 获取预测结果
probabilities = torch.nn.functional.softmax(output[0], dim=0)
top5_prob, top5_catid = torch.topk(probabilities, 5) # 获取前 5 个类别
# 获取 Top-1 预测结果
top1_index = top5_catid[0].item()
top1_class_name_zh = index_to_class_name_zh[top1_index]
top1_class_name_en = index_to_class_name_en[top1_index]
top1_prob = top5_prob[0].item()
# 加载对应的标注文件
annotation_file = os.path.splitext(image_file)[0] + ".xml"
annotation_path = os.path.join(annotations_folder, annotation_file)
if os.path.exists(annotation_path):
# 解析 XML 标注文件
tree = ET.parse(annotation_path)
root = tree.getroot()
# 获取真实类别的 WordNet ID
true_class_wordnet_id = root.find("object/name").text
if true_class_wordnet_id in wordnet_id_to_index:
true_class_index = wordnet_id_to_index[true_class_wordnet_id]
true_class_name_zh = index_to_class_name_zh[true_class_index]
true_class_name_en = index_to_class_name_en[true_class_index]
# 判断 Top-1 预测是否正确
is_correct_top1 = (top1_index == true_class_index)
if is_correct_top1:
evaluation_results["correct_predictions"] += 1
else:
evaluation_results["incorrect_predictions"] += 1
# 判断 Top-5 预测是否正确
top5_indices = top5_catid.squeeze().tolist() # 去除批次维度并转换为列表
is_correct_top5 = (true_class_index in top5_indices)
if is_correct_top5:
evaluation_results["correct_top5_predictions"] += 1
# 记录详细评估信息
evaluation_results["details"].append({
"image_file": image_file,
"top1_index": top1_index,
"top1_class_name_zh": top1_class_name_zh,
"top1_class_name_en": top1_class_name_en,
"top1_prob": top1_prob,
"true_index": true_class_index,
"true_class_name_zh": true_class_name_zh,
"true_class_name_en": true_class_name_en,
"is_correct_top1": is_correct_top1,
"is_correct_top5": is_correct_top5
})
# 打印评估信息
print(f"图片: {image_file}")
print(f"Top-1 预测: {top1_class_name_zh} ({top1_class_name_en}) (概率: {top1_prob * 100:.2f}%)")
print(f"真实类别: {true_class_name_zh} ({true_class_name_en})")
print(f"Top-1 预测结果: {'正确' if is_correct_top1 else '错误'}")
print(f"Top-5 预测结果: {'正确' if is_correct_top5 else '错误'}")
else:
print(f"未找到 WordNet ID {true_class_wordnet_id} 对应的索引")
else:
print("未找到对应的标注文件")
except Exception as e:
print(f"处理图片 {image_file} 时出错: {e}")
# 更新总图片数
evaluation_results["total_images"] += 1
print("-" * 50)
# 计算准确率
evaluation_results["top1_accuracy"] = evaluation_results["correct_predictions"] / evaluation_results["total_images"]
evaluation_results["top5_accuracy"] = evaluation_results["correct_top5_predictions"] / evaluation_results["total_images"]
# 保存评估结果到 JSON 文件
output_file = "results_5000.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(evaluation_results, f, indent=4, ensure_ascii=False)
print(f"评估结果已保存到 {output_file}")运行这个代码,可能会需要一些时间。等待运行完毕会生成一个json文件,也就是包括详细的评估信息的文件,内容大致如下:
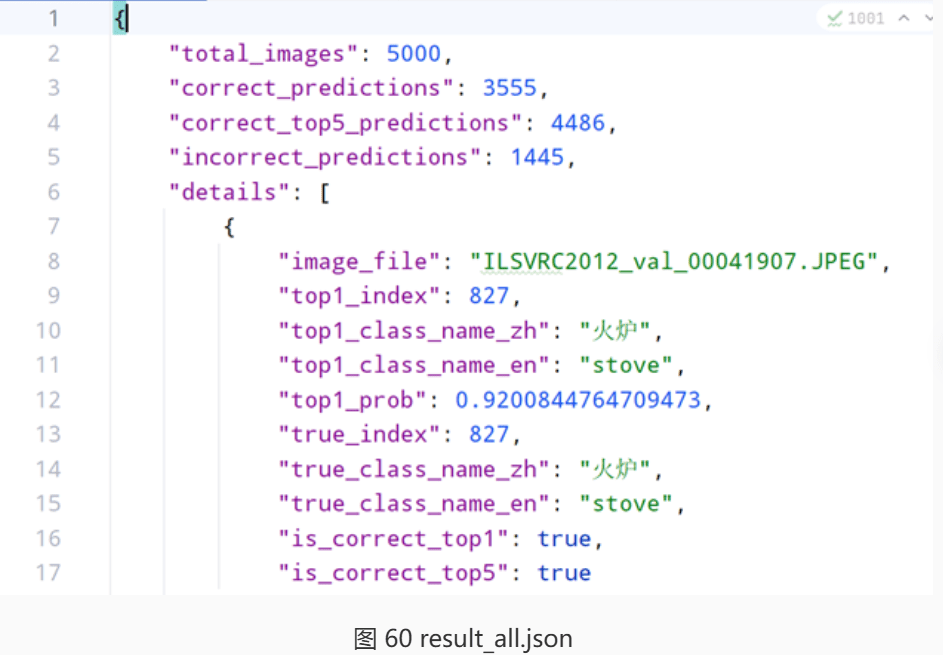
所以根据这个json文件,我们可以得到所有的评估信息。比如我们的Top1准确率大概在70%左右,Top5正确率有将近90%。基于获取的评估信息文件,可以对其进行可视化。比如,我们选取前10个出现次数最多的类别,统计其正确率:
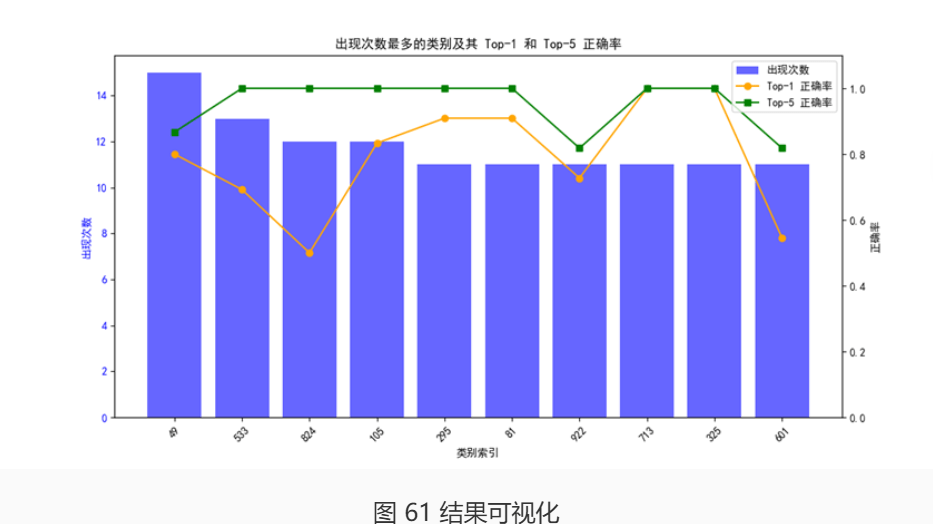
大部分的Top5正确率相比Top1正确率有提升,且正确率都在80%以上,说明我们的模型正确率还是不错的。我们还可以绘制混淆矩阵,查看对于每个类别,模型错误地将其分类成哪一个类可能性较大。不过ImageNet有1000个类,所以这里就不展示混淆矩阵了,那会是一个1000*1000大小的矩阵。
如果我们使用所有的图片进行测试,结果如下。
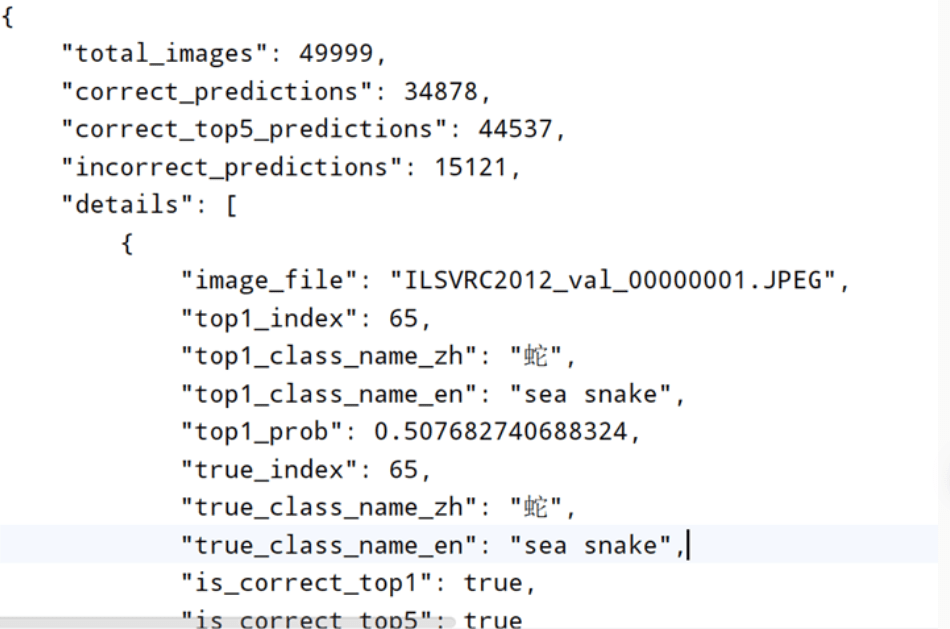
由此可以得出ResNet18的模型效果还是有提升空间的,Top1的正确率不到70%,Top5正确率在89%左右。
模型的准确性和局限性分析
前一小节,我们根据ImageNet的验证集,进行了测试,并展示了对于整个验证集的正确率,Top1在70%左右,Top5在89%左右。为什么Top1正确率较低,而Top5正确率会提高不少? 最直接的原因就是Top5给了模型更多次的机会,不过让我们继续思考背后的问题。
第一个就是数据集的问题。首先是类别太多,在ImageNet数据集中,有1000个类别,所以ResNet18拥有判断1000个类别的能力,而在其中判断正确的类别是很有挑战性的。其次,类别之间可能存在较高的相似性(例如不同品种的狗、不同类型的车辆等)。模型可能难以准确区分这些相似类别,导致Top1准确率较低,而Top5提升较大。
其次就是模型本身的问题,ResNet18的参数量相较于其他的ResNet模型(如ResNet50或ResNet101)会少很多,所以捕捉数据类别间差异的能力自然也就不如这些模型,所以导致整体准确率都不是非常高。在torch库的resnet.py文件中,我们可以看到这里提供了很多ResNet的版本,并标注了其在ImageNet上面的评估水平,我们可以参考一下。
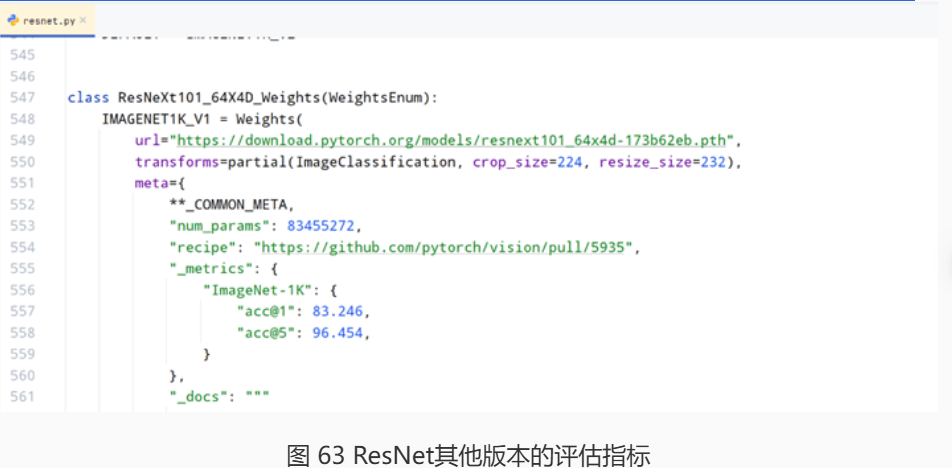
一般而言,更好的性能需要更大的参数量,训练和测试时也就需要更多的算力和时间成本。
实验总结与反思
本次实验,我们基于ResNet18预训练模型,实现了图像分类,不过本次实验的目的不仅仅只是介绍了一个用于实现图像分类的模型,更重要的是,人工智能的各个领域的下游任务,基本上都存在预训练模型,所以倘若哪一天我们遇到了一个真实的需求,比如实现一个语义分割、目标检测任务,或者其他的非视觉领域的任务,我们脑海中首先浮现出来的,不一定要是我该如何构建这样的模型?我们可以先去寻找,有没有这样的预训练模型可以供我们直接调用?通过预训练模型,我们先实现任务的基本需求,然后再在预训练模型上做出改进,比如基于少量数据集进行微调,使其在特定情况下拥有比预训练模型更好的效果。折中思路是非常重要的,很多时候,我们并不需要重复造轮子。
Comments NOTHING