

1、项目概述
1.1项目背景
在如今的智能制造与机械设计、智能化工业生产的大背景下,实现机械零件的自动化识别与分拣是智能制造、自动化生产与便携化一体式管理的核心环节。以前工厂想识别零件,基本只靠两种老办法:
1. 人工肉眼分拣:全靠工人用眼睛看、凭借经验判断。这种方法不仅让人干活特别累、速度还特别慢,同时也需要一定的时间成本用于工人的培训。而且如果工人带有主观情绪,亦或者由于疲惫或伤病导致的生理不适,会影响准确性和效率。这样的纯人工检测导致漏检或错检,无法满足高精度、大规模的生产需求。同时人力成本也是一笔大规模的支出。
2. 传统机器视觉(OpenCV):靠简单的图像计算找零件边缘、外形、颜色来分辨。基于物品的边缘及其轮廓匹配、颜色筛选等传统图像处理算法。这类方法对外界环境干扰的抵抗性较低,比如它对环境光照变化极其敏感,太亮或太暗就会出现很大的问题。若是人在日常的生活或生产中手工拍摄图片,背景复杂的时候,比如零件堆叠或存在反光时,算法的准确性就会急剧下降。且这种识别方式的适应能力很差,换一种新零件,就得重新写一大堆复杂代码才能用,费时又费力。
随着人工智能中深度学习技术的爆发,尤其是卷积神经网络(CNN)在计算机视觉领域的普及,利用AI模型自动提取零件特征并根据特征进行特异性训练,以进行零件识别,从而解决上述的2种问题是一个新的可行的解决方案。本项目旨在开发一套基于深度学习的桌面端零件识别系统,通过AI的深度学习识别零件的种类,以降低工业场景下的自动化门槛。
1.2项目目标
本项目基于 Python 与 PyTorch 深度学习框架,搭建一套稳定可靠、不容易出错、准确率较高的机械零件识别程序。设定具体量化考核指标如下:
- 识别准确率:以准备的素材图片构建一套测试集上,模型对 5 类常见机械零件(螺栓、螺母、垫片、平键、齿轮)的识别准确率 80%。
- 推理速度:在 CPU 环境下单张图片推理耗时 200ms,在 GPU 环境下 50ms,满足日常乃至生产时的要求。
- 生产环境的使用:提供一键启动脚本(start.bat),用户只需要双击或者输入简单的一串命令(Linux、Shell环境下)实现环境自动检测与依赖安装,非专业人员亦可轻松部署与使用。
- 可视化操作界面:开发较为直观的图形化用户界面(GUI),能实时看到模型训练的进度,也会直接显示识别出来的零件结果,还会根据置信度的值智能判断识别的可靠程度,给出不同等级的风险提醒。
1.3 团队分工
本项目由 3名成员协作完成,具体职责分工如下:
- 陈梓轩:方案设计,提出总体的方向设计;代码测试,对其他的团队成员编写的代码进行测试,确保没有重大漏洞或其他问题,并总结代码出现的问题和其他团队成员合作修改优化,合作设计app.py主界面和一键启动脚本start.bat;演示视频的拍摄与剪辑,全权负责演示视频的拍摄与后期剪辑;模型训练,对模型进行训练优化,收集模型训练的部分素材
- 程国峰:模型训练,对模型进行训练优化;素材收集,收集模型训练的部分图片素材和视频剪辑时所需要的部分素材
- 陈颖俊:核心代码的编写,负责研究MobileNetV2模型原理,设计迁移学习的具体实现步骤,对数据集进行预处理,使得通过不断调整训练参数和图片的优化的步骤,让小参数模型能够基本实现预定功能;编写 train.py与 predict.py核心代码,基于 Tkinter 开发 GUI 界面,合作设计start.bat一键启动脚本。
2、总体方案设计
2.1总体架构设计
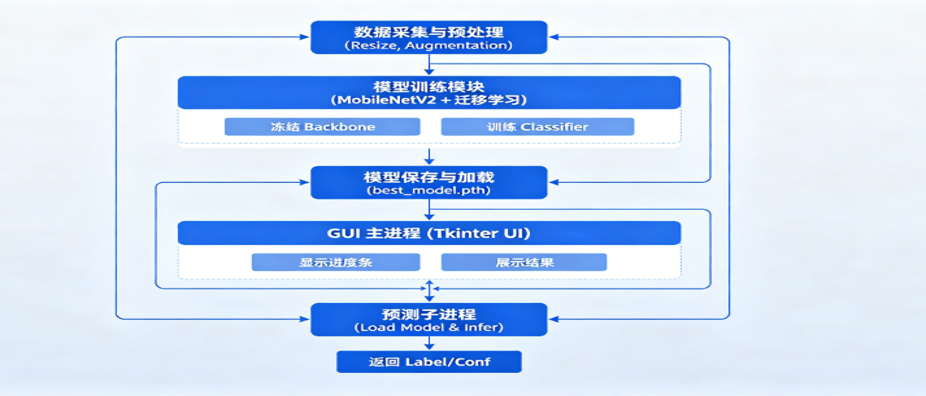
本系统采用经典的Client/Server 架构(客户端/服务器)结合子进程通信的设计模式,确保训练过程的耗时操作不会阻塞。前端app.py渲染相关结果,通过json等方式获取后端train.py与predict.py传递的参数。先是处理零件图片,调整图片大小、扩充图片样本进行数据集的初步采集与处理,再将参数传递入 MobileNetV2模型训练,通过迁移学习训练模块,分冻结骨干网络、训练分类器两步完成模型训练;训练完成后保存为可以直接长期使用的best_model.pth 模型文件,后续可以直接调取使用。整个操作窗口由 Tkinter 搭建,属于主程序,专门展示训练进度和识别结果。模型交付至基于torch和pillow的predict模块,后将结果传递给主界面。为避免耗时推理阻塞界面,单独开辟预测子进程,主、子进程双向通信,主程序下发识别任务,子程序读取模型算出零件种类和可信程度再传回,靠分开运行两个程序,保证操作界面一直流畅不卡顿。
2.2技术选型说明
Python3.12:语法简洁,代码简单好写,拥有庞大的科学计算生态和社区生态。相比C++和Java开发效率高,且入门难度低,网上也有大量教程和开源代码可以参考。
PyTorch深度学习工具:更适合做课题研究和快速搭建测试模型,社区开发者交流活跃,调用API简易方便。
MobileNetV2:轻量级AI模型,采用分层卷积计算方式。参数量小,对于小模型和小数据具有优势,推理速度快,适合个人电脑CPU和部分生产环境,低配置也能流畅运行,且精度也能满足零件分辨的使用要求。
Tkinter图形界面工具:Python自带的GUI 库。无需额外安装依赖,跨平台兼容性好,适合小型项目的初步可视化界面的实现。
2.3模块划分
数据预处理与模型训练模块(train.py):使用TorchVision Transforms、PyTorch,、MobileNetV2为主要技术栈
推理预测模块(predict.py):使用PyTorch、Pillow和训练完成后的MobileNetV2模型
界面交互模块(app.py):使用Tkinter进行界面绘制,使用json读取train.py的数据
环境配置模块(start.bat、start.sh):使用Shell进行简单的环境检测与配置
3、详细实现过程
3.1数据模块:
数据集来源:本项目采用自制数据集。通过网络爬虫和人工下载获取包含螺栓、螺母、垫片、平键、齿轮的工业图片,并通过购物平台的评论获取他人手机拍摄部分实物照片,以覆盖多个场景。
数据清洗与预处理:
1、清洗:删掉模糊不清、重复、没有零件的无效照片,只留下能用来训练的有效图片。
2、数据增强:为解决小样本过拟合问题,防止AI模型“背题”,在训练阶段引入随机水平翻转、随机角度旋转、亮度明暗细节和对比度轻微变化。
3、归一化:统一缩放至 224×224 像素,并进行标准化处理(Mean: [0.485, 0.456, 0.406], Std: [0.229, 0.224, 0.225]),以适配 ImageNet 预训练权重分布。
数据集划分:采用分层抽样法,按8:2的比例随机划分为训练集(约240张)与验证集(约60
张),并固定随机种子(SEED=42)以保证实验可复现。
3.2 模型模块
模型原理:MobileNetV2 采用深度可分离卷积替代标准卷积,大幅减少了计算量与参数量。其核心在于 Inverted Residuals 结构,即在薄层(低维)使用残差连接。
迁移学习策略:
由于本次可用的数据样本数量不多,如果直接完整训练模型,很容易出现过拟合问题。本项目采用特征提取(Feature Extraction)策略:
1、冻结:加载 ImageNet 训练好的现成模型参数后,冻结模型 features层的所有参数。这部分深度学习网络已经基本学会识别图像的一些基础信息,如线条、纹理、轮廓等,训练时不用改动。
2、微调:只更换模型末尾负责分类的输出层,(classifier[1]),将其输出维度改为和零件种类数相同的5,并更新持续训练这一层的参数。
训练参数设置:
优化器:Adam
学习率(LR):0.0005(较小的学习率防止模型“背题”,从而发生过拟合)
批次大小(Batch Size):8
训练轮次(Epochs):10(选用较低的训练轮次,防止过拟合)
性能指标:经过 10 轮训练,模型在验证集上达到85%以上的准确率,损失值稳定在1.0以下。
3.3 大模型模块(智能提示与结果解读)
虽然本项目核心识别模型为轻量级神经网络,没有结果的分析与人机交互等大模型具有的模块,但在结果分析与用户交互层面借鉴了提示词工程的设计方案,让输出结果像大模型一样可以智能输出。
应用场景:置信度分级提示与风险解读。
系统并非简单地输出一个数字,而是基于概率分布,通过人工经验和互联网得到的数据,设计了三种不同的输出提示:
| 置信度区间 | 状态 | 输出 |
| 1-0.7 | ✅ 可信 | 模型判定特征明显,可信度较高。 |
| 0.4-0.7 | ⚠️ 不确定 | 特征不明显或存在干扰,建议人工复核。 |
| 0-0.4 | ❌ 过低 | 可能为未知类别或无关图片,建议拒识。 |
这种借鉴大模型的“思维链”输出的设计模式,能够提高在实际工程中的实用效果,同时降低使用难度。
3.4 界面/交互模块
界面搭建:基于 Tkinter 构建简洁的桌面应用。
布局:界面从上到下竖直排列,包含标题、训练按钮、进度条、训练状态提示栏、预测按钮及结果显示。
通信机制:为了解决Tkinter主线程容易在执行任务时阻塞导致卡顿的问题,采用定时查询JSON文件的方式传输信息。
1、train.py每完成一个Epoch,将进度写入progress.json。
2、app.py每隔 0.5秒读取该文件,更新进度条位置与训练状态提示栏文本。
3、训练结束后删除progress.json文件,防止2次训练时出现状态残留的问题。
实现效果:点击“开始训练”后,GUI界面不卡顿。进度条实时刷新,训练完成后自动弹窗提示。
4、测试与结果分析
4.1 功能测试
| 测试功能 | 输入 | 预期结果 | 实际结果 |
| 模型训练 | 点击“开始训练” | 进度条走动,显示 Loss/Acc | 符合预期 |
| 图片预测 | 选择 test2.jpg | 结果:齿轮,置信度高 | 识别为齿轮,Conf=0.89 |
| 低置信度处理 | 选择模糊图片和无关图片 | 提示“置信度过低” | 提示“建议人工确认” |
| 一键启动 | 双击 start.bat | 自动安装依赖并运行 | 环境配置成功 |
| 异常处理 | 未安装环境 | 提示需安装Python | 程序捕获异常并提示 |
4.2 性能测试
| 测试指标 | 测试环境 | 测试结果 | 评价 |
| 训练准确率 | GPU (RTX 5070TI Laptop) | 91.32% | 达到预期目标 |
| 单图推理耗时 | CPU(AMD R9 9955HX) | ~45 ms | 满足实时性 |
| 单图推理耗时 | GPU (RTX 5070TI Laptop) | ~12 ms | 极快 |
| 模型大小 | 磁盘占用 | ~100 MB | 轻量,易部署 |
4.3 稳定性测试
- 断网环境测试:在保证已经安装了torch、torch vision、pillow等相关依赖库的情况下,通过加载本地权重mobilenet_v2-b0353104.pth模型,即使是在没有网络或者网络出现问题、SSL证书报错等情况下,也可以不依赖联网下载模型,程序正常启动并按期运行。
- 异常输入测试:当输入图片不满足要求,甚至出现文件损坏等无法正常导入predict.py进行预测时,系统通过try-except的方法,不会导致闪退,而是返回错误提示,以供分析。
- 重复训练测试:app.py在第一次点击“开始训练”按钮时锁定了相关按钮,确保正常情况下一般不会出现多开情况。
5. 总结与展望
5.1 项目完成情况
本项目按期完成了期望目标。通过使用MobileNetV2模型,并配合相应的训练方式,成功构建了一套零件识别系统,能够以85%以上的准确率识别5大零件,超过了预期目标。同时,基于Python自带的Tkinter开发了简易图形化界面,使新手也能轻松使用。并提供了 start.bat一键启动脚本,实现了由课程实验到实际生产的进步。
5.2 问题与解决方案
1. 首次预测卡顿:分析发现点击按钮后会重复import从而导致模型重复加载。将import移至启动时,在启动时加载模型,从而解决问题。
2. SSL 证书下载失败:测试时发现Python 3.13 + Windows 10环境访问 PyTorch Hub 证书校验失败。通过手动下载 mobilenet_v2-b0353104.pth权重,代码改为 weights=None并本地加载。
- 过拟合:训练集 Acc 高,验证集 Acc 低。通过智能预处理,限制模型训练的方式,同时减少训练轮次数,防止“背题”
5.3 不足与改进方向
尽管系统表现良好,但仍存在以下不足:
1.类别有限:目前仅支持 5 类零件,且未包含“光轴”等类别。未来可扩充数据集,支持更多种类的工业零件。
2.无定位功能:目前仅能识别单个图像内的单个零件,无法标注多个零件在图中的位置并智能切割识别。后续可引入 YOLO 系列目标检测算法。
3.部署形态单一:目前仅为桌面端应用。未来可转换为Web网页服务,通过HTTP传输文件至后端,经过处理后再传回前端显示。
6. 补充材料
6.1、核心代码
6.1.1、项目结构:
part_classification/
├── data/
│ └── train_data/
│ ├── 螺栓/
│ ├── 螺母/
│ ├── 垫片/
│ ├── 平键/
│ └── 齿轮/
├── models/
│ └── best_model.pth
├── test_img/
│ ├── test1.jpg
│ ├── test2.jpg
│ ├── test3.jpg
│ ├── test4.jpg
│ └── test5.jpg
├── app.py
├── predict.py
├── main.py
├── requirements.txt
└── README.md
6.1.2核心代码:
(1)app.py
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from predict import predict # 启动时加载模型
import subprocess, threading, sys, os, json, time
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
TRAIN_SCRIPT = os.path.join(BASE_DIR, "train.py")
PROGRESS_FILE = os.path.join(BASE_DIR, "models", "progress.json")
# ===================== 训练 =====================
def start_train():
train_btn.config(state="disabled")
progress_bar.config(mode="indeterminate")
progress_bar.start(10)
status_label.config(text="训练中...")
def task():
proc = subprocess.Popen(
[sys.executable, TRAIN_SCRIPT],
cwd=BASE_DIR
)
# 轮询进度文件
while proc.poll() is None:
if os.path.exists(PROGRESS_FILE):
try:
if os.path.getsize(PROGRESS_FILE) == 0:
time.sleep(0.1)
continue
with open(PROGRESS_FILE, "r", encoding="utf-8") as f:
p = json.load(f)
if "epoch" not in p:
continue
progress_bar.stop()
progress_bar.config(
mode="determinate",
maximum=p["total"],
value=p["epoch"]
)
status_label.config(
text=f"Epoch {p['epoch']}/{p['total']} "
f"Loss: {p['loss']} "
f"Acc: {p['acc']:.4f}"
)
except json.JSONDecodeError:
pass
time.sleep(0.5)
# 训练结束
progress_bar.stop()
progress_bar.config(mode="determinate", maximum=1, value=1)
status_label.config(text="✅ 训练完成")
train_btn.config(state="normal")
messagebox.showinfo("完成", "模型训练完成 ✅")
threading.Thread(target=task, daemon=True).start()
# ===================== 预测 =====================
def start_predict():
path = filedialog.askopenfilename(filetypes=[("图片", "*.jpg *.png *.jpeg")])
if not path:
return
res = predict(path)
result_label.config(text=f"预测结果:{res['label']}")
conf_label.config(text=f"置信度:{res['confidence']:.4f}")
hint_label.config(text=res["status"])
# 颜色提示
if res["confidence"] < 0.4:
hint_label.config(fg="red")
elif res["confidence"] < 0.7:
hint_label.config(fg="orange")
else:
hint_label.config(fg="green")
# ===================== GUI =====================
root = tk.Tk()
root.title("零件识别系统")
root.geometry("520x360")
tk.Label(root, text="零件识别系统", font=("微软雅黑", 16)).pack(pady=10)
# 训练按钮
train_btn = tk.Button(
root, text="🚀 开始训练", width=20, height=2,
command=start_train
)
train_btn.pack(pady=5)
# 进度条
progress_bar = ttk.Progressbar(root, length=440, mode="indeterminate")
progress_bar.pack(pady=10)
# 状态文字
status_label = tk.Label(root, text="等待训练...", font=("微软雅黑", 10))
status_label.pack()
# 预测按钮
tk.Button(
root, text="🖼️ 选择图片预测", width=20, height=2,
command=start_predict
).pack(pady=15)
# 预测结果
result_label = tk.Label(root, text="预测结果:", font=("微软雅黑", 12))
result_label.pack()
conf_label = tk.Label(root, text="置信度:", font=("微软雅黑", 12))
conf_label.pack()
hint_label = tk.Label(root, text="", font=("微软雅黑", 10))
hint_label.pack(pady=(5, 10))
root.mainloop()(2)train.py
# =========================
# 1. 导入所需库
# =========================
import os
import json
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
from torchvision.models import mobilenet_v2
# =========================
# 2. 固定随机种子(保证实验可复现)
# =========================
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# =========================
# 3. 基础配置(新手只改这里)
# =========================
DATA_DIR = "./data/train_data" # 训练数据集路径
SAVE_DIR = "./models" # 模型保存路径
BATCH_SIZE = 8 # 每批训练样本数
EPOCHS = 10 # 训练轮数
LR = 0.0005 # 学习率
os.makedirs(SAVE_DIR, exist_ok=True)
# 自动选择运行设备(有 GPU 用 GPU,否则用 CPU)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"✅ 当前使用设备:{DEVICE}")
# =========================
# 4. 图像预处理(训练 + 验证)
# =========================
transform = transforms.Compose([
transforms.Resize((224, 224)), # 统一输入尺寸
transforms.RandomHorizontalFlip(), # 随机水平翻转(增强)
transforms.RandomRotation(20), # 随机旋转(增强)
transforms.ColorJitter(brightness=0.4, contrast=0.4),
transforms.ToTensor(), # 转为 PyTorch Tensor
transforms.Normalize( # 标准化(ImageNet 分布)
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# =========================
# 5. 加载数据集
# =========================
dataset = datasets.ImageFolder(DATA_DIR, transform=transform)
# 类别名称(文件夹名)
class_names = dataset.classes
num_classes = len(class_names)
# 训练集 : 验证集 = 8 : 2
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_ds, val_ds = random_split(
dataset,
[train_size, val_size],
generator=torch.Generator().manual_seed(SEED)
)
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE, shuffle=False)
# =========================
# 6. 加载预训练模型(MobileNetV2)
# =========================
# 使用本地预训练权重,避免联网下载失败
WEIGHT_PATH = "./models/mobilenet_v2-b0353104.pth"
model = mobilenet_v2(weights=None)
state = torch.load(WEIGHT_PATH, map_location="cpu")
model.load_state_dict(state)
print("✅ 已加载本地 MobileNetV2 权重")
# 冻结特征提取层(防止小样本过拟合)
for param in model.features.parameters():
param.requires_grad = False
# 替换分类头,适配当前零件类别数
model.classifier[1] = nn.Linear(model.last_channel, num_classes)
model.classifier[1].requires_grad = True
# 将模型放到指定设备
model.to(DEVICE)
# =========================
# 7. 损失函数与优化器
# =========================
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(
model.classifier[1].parameters(), # 只优化最后一层
lr=LR
)
best_acc = 0.0
# =========================
# 8. 开始训练
# =========================
for epoch in range(EPOCHS):
model.train()
train_loss = 0.0
# ---------- 训练阶段 ----------
for x, y in train_loader:
x, y = x.to(DEVICE), y.to(DEVICE)
out = model(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
# ---------- 验证阶段 ----------
model.eval()
correct, total = 0, 0
with torch.no_grad():
for x, y in val_loader:
x, y = x.to(DEVICE), y.to(DEVICE)
pred = model(x).argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
acc = correct / total
avg_loss = train_loss / len(train_loader)
print(f"Epoch {epoch+1}/{EPOCHS} | Loss: {avg_loss:.4f} | Acc: {acc:.4f}")
# ---------- 保存进度(给 GUI 用) ----------
progress = {
"epoch": epoch + 1,
"total": EPOCHS,
"loss": round(avg_loss, 4),
"acc": round(acc, 4)
}
tmp = os.path.join(SAVE_DIR, "progress.tmp.json")
final = os.path.join(SAVE_DIR, "progress.json")
with open(tmp, "w", encoding="utf-8") as f:
json.dump(progress, f)
os.replace(tmp, final)
# ---------- 保存最优模型 ----------
if acc > best_acc:
best_acc = acc
torch.save({
"model_state": model.state_dict(),
"class_names": class_names
}, os.path.join(SAVE_DIR, "best_model.pth"))
# =========================
# 9. 清理进度文件
# =========================
progress_file = os.path.join(SAVE_DIR, "progress.json")
if os.path.exists(progress_file):
os.remove(progress_file)
print("✅ 训练完成,最优模型已保存")(3)predict.py
# =========================
# 1. 导入所需库
# =========================
import os
import torch
from PIL import Image
from torchvision import transforms
from torchvision.models import mobilenet_v2
# =========================
# 2. 基础配置
# =========================
MODEL_PATH = "./models/best_model.pth" # 训练好的模型
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# =========================
# 3. 图像预处理(必须与训练时一致)
# =========================
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# =========================
# 4. 加载模型(全局只加载一次)
# =========================
checkpoint = torch.load(MODEL_PATH, map_location=DEVICE)
CLASS_NAMES = checkpoint["class_names"]
# 加载 MobileNetV2 预训练权重
WEIGHT_PATH = "./models/mobilenet_v2-b0353104.pth"
model = mobilenet_v2(weights=None)
state = torch.load(WEIGHT_PATH, map_location="cpu")
model.load_state_dict(state)
# 替换分类头并加载训练好的参数
model.classifier[1] = torch.nn.Linear(model.last_channel, len(CLASS_NAMES))
model.load_state_dict(checkpoint["model_state"])
model.to(DEVICE)
model.eval() # 切换到推理模式
print("✅ 模型加载完成")
# =========================
# 5. 单张图片预测函数
# =========================
def predict(img_path):
"""
输入:图片路径
输出:类别名称、置信度、状态提示
"""
if not os.path.exists(img_path):
raise FileNotFoundError(f"图片不存在: {img_path}")
# 读取图片并预处理
img = Image.open(img_path).convert("RGB")
img = transform(img).unsqueeze(0).to(DEVICE)
# 推理(不计算梯度)
with torch.no_grad():
out = model(img)
prob = torch.softmax(out, dim=1)
idx = prob.argmax().item()
conf = prob[0][idx].item()
# 置信度分级提示
if conf < 0.4:
status = "❌ 置信度过低,建议人工确认"
elif conf < 0.7:
status = "⚠️ 识别结果不确定,请复核"
else:
status = "✅ 识别结果可信"
return {
"label": CLASS_NAMES[idx],
"confidence": conf,
"status": status
}
# =========================
# 6. 命令行测试(可选)
# =========================
if __name__ == "__main__":
test_img = "./test_img/test1.jpg"
res = predict(test_img)
print(f"预测结果:{res['label']}")
print(f"置信度:{res['confidence']:.4f}")
print(res["status"])6.1.3代码打包文件
6.2项目演示视频
Comments NOTHING