

前言
准备好了实验环境,我们开始第一个机器学习算法——线性回归的实战!
线性回归就像机器学习的“Hello, World!”,简单却充满力量,是理解更复杂模型的基石。本节实验,我们将完成机器学习领域非常经典的一个案例:房价预测。
为什么选择线性回归?
线性回归是机器学习中,最简单的模型之一,它的核心思想就是通过一条直线(或者超平面)来拟合数据。模型的公式简单,易于理解,非常适合入门。而且,线性回归虽然简单,但它涵盖了机器学习的核心流程,包括数据的准备、预处理、模型的构建、训练、评估等一整套机器学习算法的流程。所以,通过线性回归的实战,我们可以全面了解机器学习算法构建、应用过程中的整个工作流程,为后续更复杂的模型打下坚实的基础。
实验数据准备
在搭建模型之前,我们需要准备一下实验所需要的数据。本次实验我们将使用加州房价数据集(California Housing Dataset),这是机器学习领域中一个经典的回归问题数据集,广泛用于教学和实验。它包含了加州不同地区的房屋信息,目标是预测房屋的中位数价格。
想要获取这个数据集非常简单。在上一节中,我们已经安装了sklearn库,它提供了便捷的接口来加载加州房价数据集。为了后续更方便地分析和使用这些数据,我们可以将其下载到本地,并保存为 CSV 文件。
# 导入我们将要用到的库
# sklearn.datasets提供了许多数据集接口, 我们可以直接调用加载数据
from sklearn.datasets import fetch_california_housing
# 为导入的库起别名, 方便后续调用
import pandas as pd
# 加载加州房价数据集
california = fetch_california_housing()
# 将数据集转换为Pandas DataFrame, 这样方便直接调用to_csv方法保存为csv文件
data = pd.DataFrame(california.data, columns=california.feature_names)
data['Price'] = california.target # 添加目标值的数据
# 保存数据到本地CSV文件
data.to_csv('california_housing.csv', index=False)保存为 CSV 文件后,我们可以直接在本地查看数据。然而,加州房价数据集包含了两万多条房价数据,如果直接查看原始数据,很难快速掌握数据集的基本信息。这时,我们可以借助Pandas这个强大的数据分析库,来对数据集进行初步的探索和分析。
通过Pandas,我们可以轻松查看数据的统计特征、分布情况以及字段之间的关系,为后续的建模和分析打下坚实的基础:
import pandas as pd
# 从CSV文件加载刚刚保存的数据
data = pd.read_csv('california_housing.csv')
# 查看房价数据集的基本信息
print("数据集的基本信息:")
print(data.info())我们可以看到如下提示信息:
数据集的基本信息:
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MedInc 20640 non-null float64
1 HouseAge 20640 non-null float64
2 AveRooms 20640 non-null float64
3 AveBedrms 20640 non-null float64
4 Population 20640 non-null float64
5 AveOccup 20640 non-null float64
6 Latitude 20640 non-null float64
7 Longitude 20640 non-null float64
8 Price 20640 non-null float64
dtypes: float64(9)
memory usage: 1.4 MB
None 从data.info()的输出中可以看到,加州房价数据集包括共计20640条数据,一共有9个字段,包括8个特征和一个目标变量,也就是房价中位数。
字段含义:
MedInc(Median Income):该地区收入的中位数,单位:万美元。
HouseAge(House Age):房屋年龄的中位数,单位:年。
AveRooms(Average Rooms):每户的平均房间数。
AveBedrms(Average Bedrooms):每户的平均卧室数。
Population:该地区的人口数。
AveOccup(Average Occupancy):每户的平均入住人数。
Latitude:该地区的纬度。
Longitude:该地区的经度。
Price(Median House Value):房屋中位数价格,单位:十万美元。这是我们需要预测的目标变量。
Non-Null Count表示非空值的个数,可以看到整个数据集没有空值,是一个非常干净、适合新手入门的数据集!
Dtype表示数据的类型。上述的9个字段都为float64,即64位浮点数类型,相较于文本类型的字段,数值类型的字段可以直接作为变量传递到模型中,省去了处理的过程。后续我们将会详细介绍对于文本数据的处理。
虽然我们已经对房价数据集的字段有了一个整体的认识,但对于数据的数值大小、分布范围等细节,我们还知之甚少。比如,收入中位数(MedInc)大概是多少?房屋年龄(HouseAge)的范围是怎样的?这些信息对于后续的数据分析和建模至关重要。别担心,强大的 Pandas 为我们提供了一个非常实用的工具——describe()!它能够快速生成数据集的统计摘要,帮助我们直观地了解数据的分布范围、集中趋势和离散程度。接下来,让我们一起揭开数据的神秘面纱,看看这些数值到底处于什么样的范围吧!
# 查看数据集的统计描述
print("\n数据集的统计描述:")
print(data.describe())得到如下提示:
数据集的统计描述:
MedInc HouseAge AveRooms AveBedrms Population \
count 20640.000000 20640.000000 20640.000000 20640.000000 20640.000000
mean 3.870671 28.639486 5.429000 1.096675 1425.476744
std 1.899822 12.585558 2.474173 0.473911 1132.462122
min 0.499900 1.000000 0.846154 0.333333 3.000000
25% 2.563400 18.000000 4.440716 1.006079 787.000000
50% 3.534800 29.000000 5.229129 1.048780 1166.000000
75% 4.743250 37.000000 6.052381 1.099526 1725.000000
max 15.000100 52.000000 141.909091 34.066667 35682.000000
AveOccup Latitude Longitude Price
count 20640.000000 20640.000000 20640.000000 20640.000000
mean 3.070655 35.631861 -119.569704 2.068558
std 10.386050 2.135952 2.003532 1.153956
min 0.692308 32.540000 -124.350000 0.149990
25% 2.429741 33.930000 -121.800000 1.196000
50% 2.818116 34.260000 -118.490000 1.797000
75% 3.282261 37.710000 -118.010000 2.647250
max 1243.333333 41.950000 -114.310000 5.000010 通过 describe(),我们可以清晰地看到每个数据特征的详细统计信息,包括数据的数量、均值、标准差、最小值、四分位数以及最大值等。这些统计指标为我们揭示了数据的分布规律和集中趋势。结合字段的具体含义和单位,我们能够更全面地理解数据集的特征分布。例如,收入中位数(MedInc)的均值约为 3.87 万美元,而房价(Price)的中位数约为 1.797(十万美元)。通过这些信息,我们对数据有了更加清晰的了解。
数据集的基本情况我们已然了解,那么最后一步,我们需要将数据集处理成可以直接输入到模型的形式,我们需要预测房价,那总要有数据给我们预测吧?所以我们要将数据集划分成训练集和测试集,训练集用于训练我们的模型,而测试集可以评估我们的模型效果究竟如何,另外,我们需要将输入变量和目标变量分离开来,假如我们的测试集中还带有真实的房价,那似乎就不用我们预测了吧!
划分训练和测试集的逻辑较为简单,相信大家可以独立完成代码的书写,这里我们同样可以使用sklearn库自带的工具函数进行数据集的划分:
注意:在划分数据集前,我还添加了标准化的代码,由于线性回归模型对特征的尺度比较敏感,因此我们通常需要对特征进行标准化处理,使得每个特征的均值为 0,标准差为 1。
# 导入sklearn库中的数据分割函数
from sklearn.model_selection import train_test_split
# 导入sklearn中的标准化函数
from sklearn.preprocessing import StandardScaler
# 分割特征和目标变量
X = data.drop('Price', axis=1) # 将Price列移除,axis=1表示移除Price这一列,而不是行
y = data['Price'] # 目标变量
# 新建标准化对象
scaler = StandardScaler()
# 调用标准化对象的方法对X标准化
X = scaler.fit_transform(X)
# 划分训练集和测试集, 必须传入原始的是 X特征数据和 y目标变量
# test_size表示测试集占总数据集的比例, 这里选择0.2,表示训练集:测试集 = 4:1. 不写默认0.25.
# random_state表示随机种子, 可以保证每次随机分割的结果是一样的, 保证实验的可复现性.
# 设置为42是一个传统, 关于42的典故大家可以自行搜索. 宇宙的答案)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("训练集大小:", X_train.shape)
print("测试集大小:", X_test.shape)得到如下信息:
训练集大小: (16512, 8)
测试集大小: (4128, 8)可以看到,我们成功地将数据集划分为了训练集和测试集。并且还去掉了房价这个目标变量,以便于我们后续对线性回归模型进行训练和评估。下面就正式进入线性回归模型的构建!
线性回归模型的实现
这一小节,我们将手动构建一个线性回归模型,虽然sklearn库中有现成封装好的模型可以调用,但手动实现一个线性回归模型是一个非常有意义的过程,在手动实现的过程中,我们可以更深入地理解线性回归的原理,包括损失函数、梯度下降等核心概念。我们将仅使用numpy库,构建我们的模型,并手写损失函数、梯度下降以迭代优化的我们的模型。
线性回归的目标是找到一组权重w和偏置b,使得模型的预测值尽可能接近真实值。模型预测的公式为:
我们如何使用Python代码实现上述公式、构建线性回归模型?最简单的方法是:取出数据集的每一行,也就是拿到每一个样本,这是一个包含8个特征的类似列表的数据结构,同样地,我们的权重w也需要一个长度相等的列表来表示。这样,两个列表对应位置的元素相乘、再求和即可完成公式的前半部分,最后也只需要再加上一个偏置b即可完成预测值的计算。
这种方法虽然直观,并易于理解,但在实际应用中效率较低,尤其是在数据集规模较大时(例如本次实验中的上万条数据),逐行计算会导致巨大的时间开销。有没有快捷且高效的方法呢?
答案是可以的!但我们可能需要用到一些基础的线性代数知识。假设我们的数据集共有m个样本,每一个样本有n个特征。这样,整个测试集可以表示为一个m行n列的矩阵X。那么,如何表示参数w呢?同样地,可以将w看作一个列向量,长度等同于X的列数n,这样,上述公式就可以使用矩阵乘法来表示:
公式看起来更加简洁了,继续思考一个问题,能不能将偏置b也用矩阵乘法表示?
答案仍然是可以!我们可以仅使用一个矩阵乘法来表示式(1)。在变量X中添加一列全为1的值,同时扩充w的长度以匹配X的列数,数值为b,然后就可以用X和w的矩阵乘法来表示线性回归运算:
import numpy as np
# np.c_ 表示按列连接两个矩阵,是np.concatenate()函数的简化形式,只能按列拼接
# 等价于X_train = np.concatenate((X_train, np.ones(X_train.shape[0])), axis=1)
# np.ones() 表示生成全1的数组,形状为X_train.shape[0],即测试集的数据个数
# 测试集同理
# X_train = [[1, 2], ==> [[1, 2, 1],
# [3, 4], [3, 4, 1],
# [5, 6]] [5, 6, 1]]
X_train = np.c_[X_train, np.ones(X_train.shape[0])]
X_test = np.c_[X_test, np.ones(X_test.shape[0])]添加全1列用于后续表示偏置
# 下面的代码演示了利用矩阵乘法实现线性回归的过程, 注意偏置b的引入过程:
# [[1, 2], * [2, 2].T + 3 = [9, 17].T
# [3, 4]
# ==> 利用X和w的修改,实现偏置b的引入
# [[1, 2, 1], * [2, 2, 3].T = [9, 17].T
# [3, 4, 1]]
# .T表示转置
# * 表示矩阵乘法
# 初始化参数
np.random.seed(42)
w = np.random.randn(X_train.shape[1]) # 随机初始化权重,随机种子保证可以复现随机初始化w
通过以上两步操作,我们对特征矩阵X进行了扩充,添加了一列全为1的值作为偏置项。同时,我们也相应地扩展了权重向量w的长度,使其与扩充后的X维度相匹配。这样一来,我们就可以通过简单的矩阵乘法来实现线性回归模型的预测公式:
你似乎在想下面我们会用Python手写一个矩阵乘法?那并不是此次实验的重点!在numpy中,矩阵乘法非常容易实现,只需要调用dot即可一行代码实现矩阵乘法。
# 矩阵乘法实现线性回归
y_pred = X_test.dot(w.T)恭喜你!成功地完成了线性回归模型的构建!这样输出的y_pred即是我们的模型所预测的房价。
不过,当我们输出y_pred的值,再与真实的房价对照,似乎我们的模型效果十分糟糕!你大概能猜到原因:我们的w只是一个随机初始化的值,所以这样预测的效果一定好不到哪里去,我们会在下一小节详细地介绍如何根据训练集的数据优化我们的参数。
模型参数的含义与优化方法
在上一节中,我们完成了线性回归模型的构建,虽然模型尚未优化,但我们已经迈出了机器学习的第一步!模型的预测效果如何,是否能够准确地反映真实数据的规律,还取决于模型参数的选择和优化。那么,这些参数究竟代表了什么?我们又该如何调整它们,使模型的性能达到最优呢?
还记得我们如何定义真实值和我们预测的值之间的差异吗?没错,使用均方误差(MSE):
这就是我们的损失函数,损失函数同时也称之为目标函数,因为我们的目标就是找到最优的参数,使得损失函数的值最小,此时说明我们的预测结果与真实值非常接近。
那我们首先来定义损失函数:
def compute_loss(X, y, w):
m = len(y) # 样本数量
y_pred = X.dot(w.T) # 预测值
loss = (1 / (2 * m)) * np.sum((y_pred - y) ** 2) # 均方误差
return loss损失函数的代码比较容易理解,loss即为根据预测值和真实值,计算出来的损失。
有了损失之后,我们该如何进行参数的优化?是的!梯度下降。进行梯度下降我们需要获得损失函数对w的梯度,需要对w求偏导:
根据式(5),我们可以手动实现梯度下降:
def gradient_descent(X, y, w, learning_rate, num_epochs):
m = len(y) # 样本数量
losses = [] # 记录损失值
for epoch in range(num_epochs):
y_pred = X.dot(w.T) # 预测值
error = y_pred - y # 误差
gradient = (1 / m) * X.T.dot(error) # 计算梯度
w -= learning_rate * gradient # 更新参数
# 记录损失值
loss = compute_loss(X, y, w)
losses.append(loss)
# 每100次迭代打印损失值
if (epoch + 1) % 100 == 0:
print(f"Epoch {epoch + 1}, Loss: {loss}")
return w, losses看到这一连串的代码,你是不是云里雾里,可能瞬间失去了对于机器学习的热情,但是请不要着急,让我逐一解读这些代码,你会发现其实它们非常容易理解!
首先将目光聚焦于函数签名部分:
def gradient_descent(X, y, w, learning_rate, num_epochs):我们总共需要5个参数,分别是训练集的输入特征X,训练集的目标变量y,需要更新的参数w,包含了权重和偏置,以及两个超参数:学习率learning_rate和总的迭代次数num_epochs。超参数指的是人为设置的一组参数,与模型的关系不大,但是会影响模型最后的训练效果。所以如何选好一组超参数自然也是一门学问。学习率指的是每次更新模型的参数时,走的步子的大小。我们知道,在梯度更新时,需要沿着梯度的反方向更新参数,那么问题来了,该更新多少呢?1个梯度的大小,还是10个梯度的大小?这就要由学习率来决定了;总的迭代次数指的是模型训练阶段,总共要进行多少次的梯度下降优化,这个参数直接关系到训练阶段的时间消耗。
搞清了梯度下降所需的全部参数后,我们进入函数的内部一探究竟。
梯度下降的核心代码在迭代阶段:y_pred表示根据训练样本X和我们当前的参数w所预测的结果,与真实值y的差异记为error,也就是公式中括号的中的预测值和真实值做差。注意由于我们所有的运算都是在整个训练集上的,所以没有出现样本的迭代,所以不要因为没有一个进行m次的for循环而感到奇怪。
下一行gradient的计算,就是将error和X相乘然后除以样本的个数,两行代码完成的其实就是公式的内容。那么先前定义的计算损失的那个函数呢?既然我们通过这两行代码完成了计算偏导数获得梯度,可以进行梯度下降的实现,那还要计算损失的函数干什么?很好的问题!的确,我们并没有对计算损失的函数求偏导数,从而获得梯度,而是直接根据公式的结果,使用更加简单的方式实现了梯度的计算,但是计算损失仍然有必要!
首先,我们在更新迭代时,如何实时了解模型的训练情况?难道只能等到训练结束后,放在测试集上跑一下?显然过于低效!我们可以直接在训练阶段就计算损失,然后每隔固定迭代次数,就打印一下训练的损失,这样,我们可以了解当前损失是否仍在继续下降,下降的幅度如何。假如我们的训练损失在200轮以后就没有明显的变化了,也就是训练到损失收敛了,那么我们就可以将迭代次数调整到200轮附近,以免过大的训练时间和资源开销。同时,记录损失值也可以为我们最后可视化训练结果做好准备,并在最后评估测试效果时提供重要的指标。
回归正题,获得梯度之后,我们根据学习率,进行梯度的参数的更新,沿着梯度的反方向更新learning_rate个梯度大小,这样就完成了一次梯度下降!后面就是将损失添加到一个列表中,以便后续进行训练阶段的可视化,还有每隔固定轮数打印损失,查看是否收敛等。
现在对这个梯度下降的函数是不是没有那么畏惧了?相信我们对于人工智能的学习也会这样一步一步,逐渐深入,由陌生到熟悉的。
设置好超参数,我们就可以运行了:
# 设置超参数
learning_rate = 0.001
num_epochs = 1000
# 训练模型
w, losses = gradient_descent(X_train, y_train, w, learning_rate, num_epochs)
# 打印最终参数
print("训练后的权重和偏置:", w)运行得到
Epoch 100, Loss: 0.9220729667823013
Epoch 200, Loss: 0.8298616116306854
Epoch 300, Loss: 0.7555300018292121
Epoch 400, Loss: 0.6953615663364233
Epoch 500, Loss: 0.6464596797490852
Epoch 600, Loss: 0.6065543688819726
Epoch 700, Loss: 0.5738577577886365
Epoch 800, Loss: 0.5469551927147737
Epoch 900, Loss: 0.5247226639492798
Epoch 1000, Loss: 0.5062637436836017可以看到,损失随着训练不断的迭代明显有了降低,我们手写的的梯度下降成功起作用了。
线性回归的可视化
上一小节我们成功实现了线性回归模型的训练,并间隔固定轮数输出损失的大小,这一节,我们使用matplotlib库对线性回归的训练和评估过程进行可视化。
import matplotlib.pyplot as plt
# 绘制损失函数的变化曲线
plt.figure(figsize=(8, 6))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve')
plt.show()得到图片
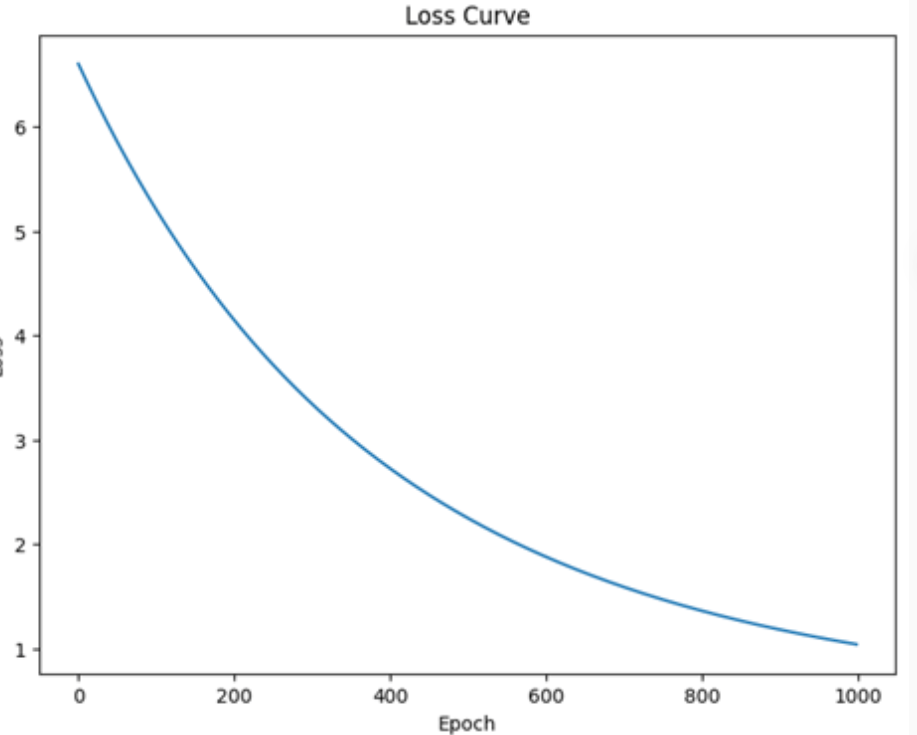
如图所示,我们的损失逐步下降,最后趋于收敛。大家不妨调整超参数的选取,比如调大训练的迭代次数到5000。再次绘图:
更改前文训练的代码为
# 设置超参数
learning_rate = 0.001
num_epochs = 5000
# 训练模型
w, losses = gradient_descent(X_train, y_train, w, learning_rate, num_epochs)
# 打印最终参数
print("训练后的权重和偏置:", w)得到提示
Epoch 100, Loss: 0.9220729667823013
Epoch 200, Loss: 0.8298616116306854
Epoch 300, Loss: 0.7555300018292121
Epoch 400, Loss: 0.6953615663364233
Epoch 500, Loss: 0.6464596797490852
Epoch 600, Loss: 0.6065543688819726
Epoch 700, Loss: 0.5738577577886365
Epoch 800, Loss: 0.5469551927147737
Epoch 900, Loss: 0.5247226639492798
Epoch 1000, Loss: 0.5062637436836017
Epoch 1100, Loss: 0.49086110954205375
Epoch 1200, Loss: 0.477939045937819
Epoch 1300, Loss: 0.46703426552508814
Epoch 1400, Loss: 0.45777307947831664
Epoch 1500, Loss: 0.4498534442859772
Epoch 1600, Loss: 0.44303077771234745
Epoch 1700, Loss: 0.43710670529934814
Epoch 1800, Loss: 0.4319200979764123
Epoch 1900, Loss: 0.42733991002630356
Epoch 2000, Loss: 0.42325943839974506
Epoch 2100, Loss: 0.41959170893575803
Epoch 2200, Loss: 0.41626575947165734
Epoch 2300, Loss: 0.4132236392332664
Epoch 2400, Loss: 0.41041798202152213
Epoch 2500, Loss: 0.4078100403067082
Epoch 2600, Loss: 0.40536809044261857
Epoch 2700, Loss: 0.40306613733806446
Epoch 2800, Loss: 0.4008828612116066
Epoch 2900, Loss: 0.39880076036811035
Epoch 3000, Loss: 0.39680545292749725
Epoch 3100, Loss: 0.394885107608247
Epoch 3200, Loss: 0.39302997940703527
Epoch 3300, Loss: 0.39123203062066747
Epoch 3400, Loss: 0.3894846213604751
Epoch 3500, Loss: 0.38778225669530775
Epoch 3600, Loss: 0.3861203799709978
Epoch 3700, Loss: 0.38449520380544777
Epoch 3800, Loss: 0.38290357183953105
Epoch 3900, Loss: 0.38134284560672843
Epoch 4000, Loss: 0.3798108119263109
Epoch 4100, Loss: 0.37830560707199445
Epoch 4200, Loss: 0.37682565465733636
Epoch 4300, Loss: 0.3753696147405413
Epoch 4400, Loss: 0.3739363421088496
Epoch 4500, Loss: 0.3725248520757348
Epoch 4600, Loss: 0.37113429242850204
Epoch 4700, Loss: 0.36976392041230266
Epoch 4800, Loss: 0.3684130838394476
Epoch 4900, Loss: 0.367081205578609
Epoch 5000, Loss: 0.3657677708139201
训练后的权重和偏置: [ 1.06362405 0.27335772 -0.49350474 0.41893378 0.04540053 -0.05340497
0.46355274 0.47540116 2.06266342]此时再次运行回归图演示代码:
import matplotlib.pyplot as plt
# 绘制损失函数的变化曲线
plt.figure(figsize=(8, 6))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve')
plt.show()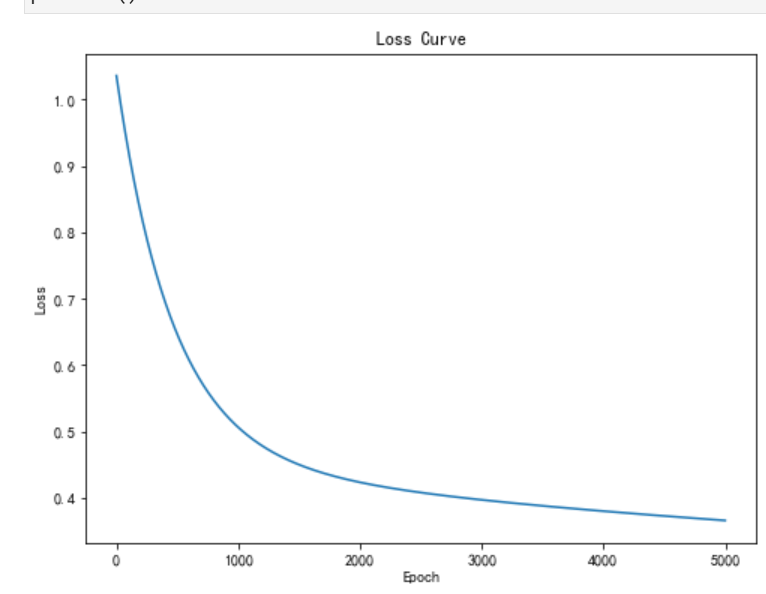
如果无法显示中文字体,可以在代码中添加:
# 解决画图无法显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False可以看到,我们得到了更小的损失。你可以尝试不同的超参数,看看如何使得损失值进一步降低。
训练更新好参数w和偏置b之后,我们可以在测试集上,对其的性能进行评估,评估的结果同样可以可视化展示出来。为了方便测试,我们可以将实现线性回归的公式封装起来:
# 定义线性回归模型
def linear_regression(X, w):
return X.dot(w)然后将测试集数据和训练好的参数w传入函数,即可获得预测的房价。我们可以打印评估的损失和可视化测试结果:
# 定义线性回归模型
def linear_regression(X, w):
return X.dot(w)
# 在测试集上进行预测
y_pred = linear_regression(X_test, w)
print('测试集损失:', compute_loss(X_test, y_test, w))
# 绘制真实值与预测值的对比图
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.5, color='blue')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
plt.xlabel('True Prices')
plt.ylabel('Predicted Prices')
plt.title('True Prices vs Predicted Prices')
# 统一 x 轴和 y 轴的刻度范围
plt.xlim(y_test.min(), y_test.max())
plt.ylim(y_test.min(), y_test.max())
plt.show()得到如下图像:
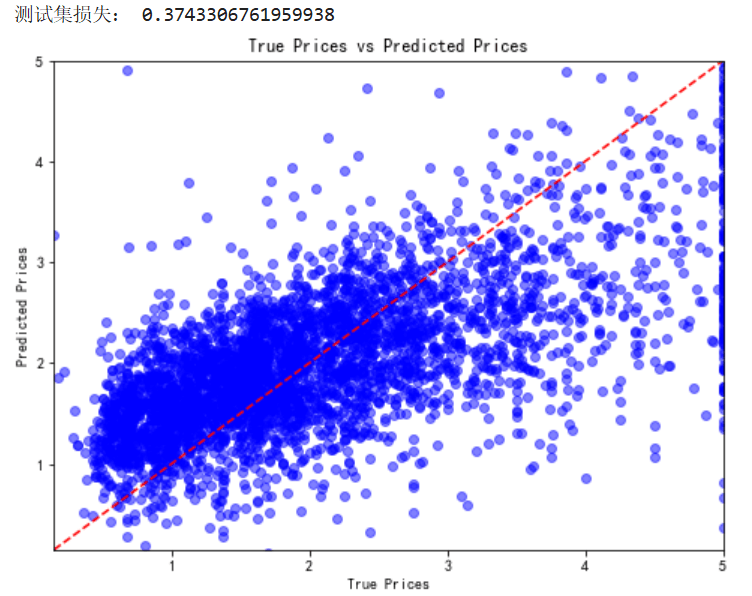
可以看到,测试集上的损失也控制在了比较小的范围内,通过可视化,我们看到样本大部分分布在了对角线及其周围,也就是测试值=真实值的情况,说明我们的模型的训练效果不错。
实验总结与反思
以上,我们成功地完成了加州房价预测的线性回归模型构建。从数据的准备、预处理,到模型搭建、损失函数的计算、梯度下降法的实现与参数优化,我们一步步走过了机器学习的核心流程。
相信大家在手动构建模型的过程中,对损失函数的意义、梯度下降的原理以及模型参数的更新机制有了更加深刻的理解。这种从零开始的实践不仅帮助我们掌握了理论知识,还让我们亲身体验了模型从无到有的构建过程,真正体会到了机器学习的魅力。
Comments NOTHING